DISCLAIMER: This post has been moved from my personal website to here, originally authored 18.12.2022
Welcome to our tutorial on how to scrape data from Reddit using the Python libraries PRAW and Openpyxl. This step-by-step guide will show you how to extract and organize data into an Excel file. Whether you have experience with data analysis and Python or are simply looking to learn more about these tools and techniques, this tutorial will provide you with the information you need to get started. By the end of this tutorial, you will be able to use PRAW and Openpyxl to create an Excel table out of Reddit posts and comments. So let’s dive in!
What is PRAW and Openpyxl?
PRAW (Python Reddit API Wrapper) is a Python library that provides a simple and easy-to-use interface for accessing and interacting with the Reddit API. It allows you to perform various actions such as retrieving posts and comments, submitting new content, and interacting with other users on Reddit. PRAW abstracts away the details of the API and provides a convenient way to access and manipulate data from Reddit using Python.
openpyxl, on the other hand, provides a simple and easy-to-use interface for reading and writing data to and from Microsoft Excel files. It allows you to work with Excel sheets in Python as if they were dictionaries, with the keys being the cell coordinates (e.g., “A1”, “B2”) and the values being the cell contents. openpyxl supports reading and writing to both .xlsx and .xlsm files, and provides a range of features for working with Excel data such as formatting cells, inserting images, and creating charts.
You can find more information about these libraries and their usage in their respective documentation:
PRAWdocumentation: https://praw.readthedocs.io/en/stable/openpyxldocumentation: https://openpyxl.readthedocs.io/en/stable/
Setting up the Reddit API
Sign up for a Reddit account if you don’t already have one. You will need an account to create an app on the Reddit developer portal.
Go to the Reddit developer portal at https://www.reddit.com/prefs/apps and log in to your Reddit account.
Click the “create app” or “create another app” button to create a new app.
Enter a name and description for your app, and select “script” as the app type. The name and description can be anything you like, but they should clearly describe the purpose of your app.
Enter a redirect URI for your app. This can be any valid URL, but it should be a URL that you control (e.g., your personal website or a page on your local development server). The redirect URI is used to redirect users back to your app after they have authorized it to access their Reddit account. In my case, I usually always use “http://localhost:8080”.
Click the “create app” button to create your app.
Once your app has been created, you will see a page with your app’s client ID and secret. These are the credentials that you will use to authenticate your app with the Reddit API.
Install the
prawlibrary usingpip install praworconda install praw, depending on your Python environment.
For this tutorial, I’ve set up an example app:
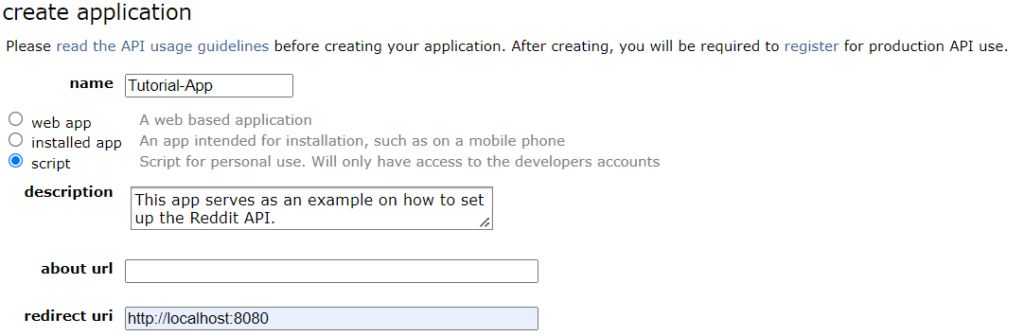
After creating the app, it is important to note following information
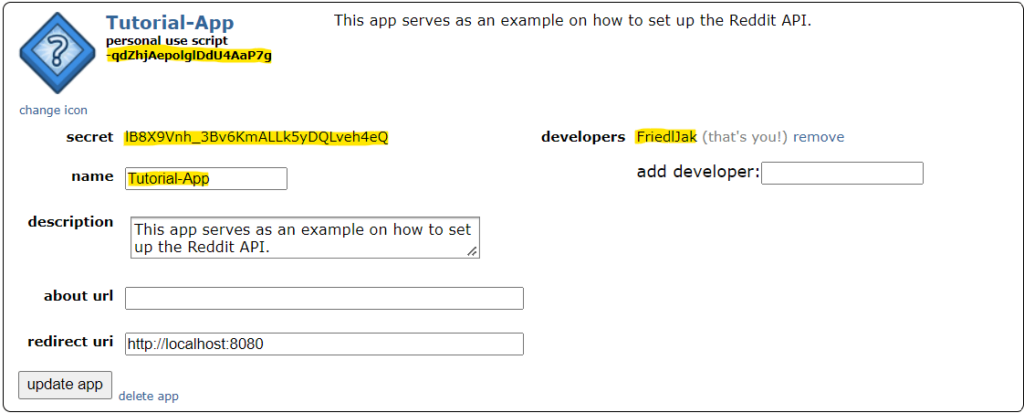
To continue with the tutorial, you will need to have this information ready:
- Your Client ID (in this case “-qdZhjAepolglDdU4AaP7g”)
- Your Client Secret (in this case ” lB8X9Vnh_3Bv6KmALLk5yDQLveh4eQ”)
- Your User Agent Name (in this case “Tutorial-App”)
- Your Reddit Username (in this case “FriedlJak”)
- Your Reddit Password
Step-by-Step Guide for Extracting Reddit Data in Python:
Now that we have all set up, we can start to use the Reddit API in Python. Simply copy-paste the following code snippets into your Python terminal. If you encounter any errors or have any questions about the code, don’t hesitate to ask for help.
Import the required libraries:
import praw
import openpyxl
import datetime Create a Reddit API client object with the details we generated in the last section of the article
reddit = praw.Reddit(client_id='[YOUR CLIENT ID]', client_secret='[YOUR CLIENT SECRET]', user_agent = '[YOUR USER AGENT NAME]', username = '[YOUR USERNAME]', password = '[YOUR PASSWORD]') Decide which Reddit posts to scrape. In this case, we use the top two posts in the “learnprogramming” subreddit with the “hot” filter. Alternative options (like scraping a specific post) will be discussed in the next section.
subreddit = reddit.subreddit('learnprogramming')
posts = subreddit.hot(limit=2) Create an Excel workbook object
workbook = openpyxl.Workbook() Define the “process_comments” function. This will late be used to recursively iterate through the comments of a given Reddit post and append them to the worksheet. This needs to be done recursively, as it is not previously known how many comments are nested in each other. Also, the date of the comment is translated into a human-readable form using the datetime library.
def process_comments(comments, parent_comment=None):
for comment in comments:
body = comment.body
author = comment.author.name if comment.author is not None else 'Deleted' # Check if the author attribute is None before accessing the name attribute
created = datetime.datetime.utcfromtimestamp(comment.created_utc).strftime('%d/%m/%Y %H:%M:%S') # convert created_utc to human-readable format
score = comment.score
values = [body, author, created, score]
if parent_comment is not None:
values.append(parent_comment.body)
else:
values.append("None")
worksheet.append(values)
process_comments(comment.replies, comment) The next step is to iterate through all the posts with a for loop. Here, the information of every individual post is appended to a newly created worksheet with the name of the post ID. Afterward, the recursion through the corresponding comments is started using the function declared in the last step.
for i, post in enumerate(posts):
title = post.title
body = post.selftext
author = post.author.name if post.author is not None else 'Deleted'
created = datetime.datetime.utcfromtimestamp(post.created_utc).strftime('%d/%m/%Y %H:%M:%S') to human-readable format
score = post.score
num_comments = post.num_comments
permalink = post.permalink
worksheet = workbook.create_sheet(f'Post {post.id}')
the post worksheet
column_headings = ['Title', 'Body', 'Author', 'Created', 'Score', 'Num Comments', 'Permalink']
worksheet.append(column_headings)
values = [title, body, author, created, score, num_comments, permalink]
worksheet.append(values)
worksheet.append([''])
column_headings = ['Comment', 'Author', 'Created', 'Score', 'Reply to']
worksheet.append(column_headings)
process_comments(post.comments, None)
At last, the workbook can be saved. In this case, the name will be set to the latest scraped post. The file will be located either at the location of the Python script or if you’ve copy-pasted the steps into your terminal, the location you’re currently in.
workbook.save(f'{post.id}.xlsx') If you prefer to run the script as a whole (which I recommend), copy the following code into a [NAME OF THE FILE].py file and execute if using the command:
python .\[NAME OF THE FILE].py import praw
import openpyxl
import datetime
# Create a Reddit API client object
reddit = praw.Reddit(client_id='[YOUR CLIENT ID]', client_secret='[YOUR CLIENT SECRET]', user_agent = '[YOUR USER AGENT NAME]', username = '[YOUR USERNAME]', password = '[YOUR PASSWORD]')
# Get a subreddit object
subreddit = reddit.subreddit('learnprogramming')
# Get a list of posts from the subreddit
posts = subreddit.hot(limit=2)
# Create a new Excel workbook
workbook = openpyxl.Workbook()
# Recursively iterate through the comments of the post
def process_comments(comments, parent_comment=None):
for comment in comments:
# Get the desired information about the comment
body = comment.body
author = comment.author.name if comment.author is not None else 'Deleted' # Check if the author attribute is None before accessing the name attribute
created = datetime.datetime.utcfromtimestamp(comment.created_utc).strftime('%d/%m/%Y %H:%M:%S') # convert created_utc to human-readable format
score = comment.score
# Create a list of values for the comment
values = [body, author, created, score]
# If the comment has a parent comment, add the parent comment's body as an additional value
if parent_comment is not None:
values.append(parent_comment.body)
else:
values.append("None")
# Add the values to the comments worksheet as a new row
worksheet.append(values)
# Recursively process the child comments
process_comments(comment.replies, comment)
# Iterate through the list of posts
for i, post in enumerate(posts):
# Create a worksheet for the current post and its comments
title = post.title
body = post.selftext
author = post.author.name if post.author is not None else 'Deleted' # Check if the author attribute is None before accessing the name attribute
created = datetime.datetime.utcfromtimestamp(post.created_utc).strftime('%d/%m/%Y %H:%M:%S') # convert created_utc to human-readable format
score = post.score
num_comments = post.num_comments
permalink = post.permalink
# Create a worksheet for the post data
worksheet = workbook.create_sheet(f'Post {post.id}')
# Add column headings to the post worksheet
column_headings = ['Title', 'Body', 'Author', 'Created', 'Score', 'Num Comments', 'Permalink']
worksheet.append(column_headings)
# Add the post data to the post worksheet as a new row
values = [title, body, author, created, score, num_comments, permalink]
worksheet.append(values)
# Add empty row
worksheet.append([''])
# Add column headings to the comments worksheet
column_headings = ['Comment', 'Author', 'Created', 'Score', 'Reply to']
worksheet.append(column_headings)
# Start the recursive processing of the comments from the top-level comments of the post
process_comments(post.comments, None)
# Save the Excel file
workbook.save(f'{post.id}.xlsx') How to scrape specific posts?
In the script above, the posts to scrape were specified by these lines:
subreddit = reddit.subreddit('learnprogramming')
posts = subreddit.hot(limit=2) In this case, the top two posts from the “learnprogramming” subreddit can be referenced in the “posts” object. Now this can already be useful if you want to extract, for example, trending topics on a subject. You will only need to specify the subreddit and the number of posts.
Another way you might want to use the PRAW library would be to specifically specify a number of posts. All you need to do is to change the two lines above to the specific posts you want to the “posts” object. The rest is the same. Here’s an example:
# List of URLs of the posts
urls = ["https://www.reddit.com/r/learnprogramming/comments/zoxtle/where_can_i_learn_the_mathmatical_background/",
"https://www.reddit.com/r/learnprogramming/comments/zp36mg/amateur_coders_what_do_you_think_can_help_you/"]
# Initialize an empty list to store the posts
posts = []
# Iterate through the list of URLs
for url in urls:
# Get the post object using the submission method
post = reddit.submission(url=url)
# Append the post object to the list
posts.append(post) Simply put this piece of code instead of the two lines from before. Now add the URLs you’re interested in to the “urls” list and you are good to go.
Conclusion and Further Resources
In conclusion, using PRAW and Openpyxl can be an effective way to extract the comment data from Reddit. These tools allow you to easily access and manipulate data from Reddit, making it easier to analyze and use in various projects.
If you want to learn more about working with Reddit data, here are some additional resources that you might find helpful:
- The PRAW documentation: https://praw.readthedocs.io/en/stable/
- The Openpyxl documentation: https://openpyxl.readthedocs.io/en/stable/
- Reddit’s API documentation: https://www.reddit.com/dev/api/
- A tutorial on using PRAW to scrape Reddit data: https://www.dataquest.io/blog/scraping-reddit-python-scrapy/
- A tutorial on using Openpyxl to work with Excel files in Python: https://www.datacamp.com/community/tutorials/python-excel-tutorial
Leave a comment and thank you for sticking around!
This post has been made in association with AI.
